ServeLoop is an open-source, minimal-scale LLM inference engine built from scratch to make the internals of model serving readable, modifiable, and measurable. Rather than wrapping an existing runtime, ServeLoop implements the core serving stack — request lifecycle, batching, KV-cache management, and GPU scheduling — as clear, isolated components designed for learning and research.
Core Architecture
The engine is structured around four main subsystems:
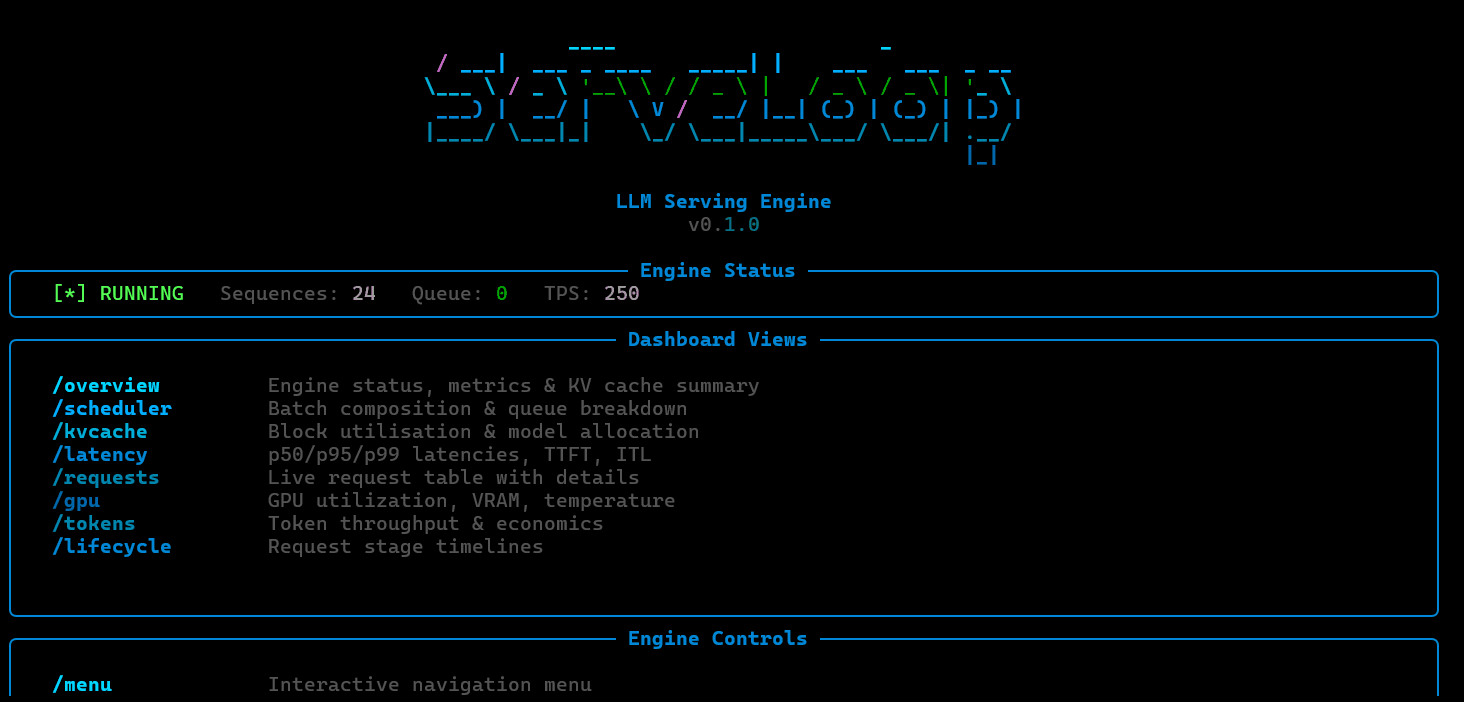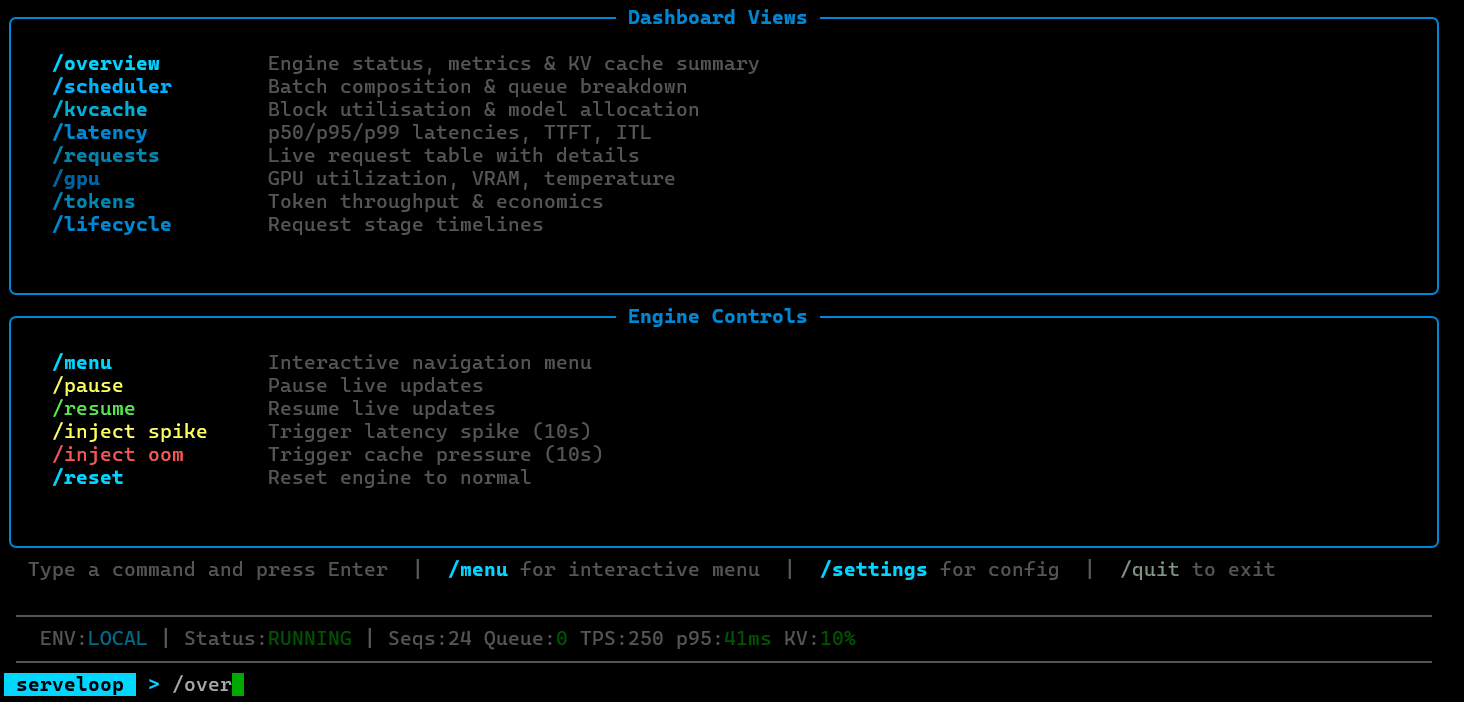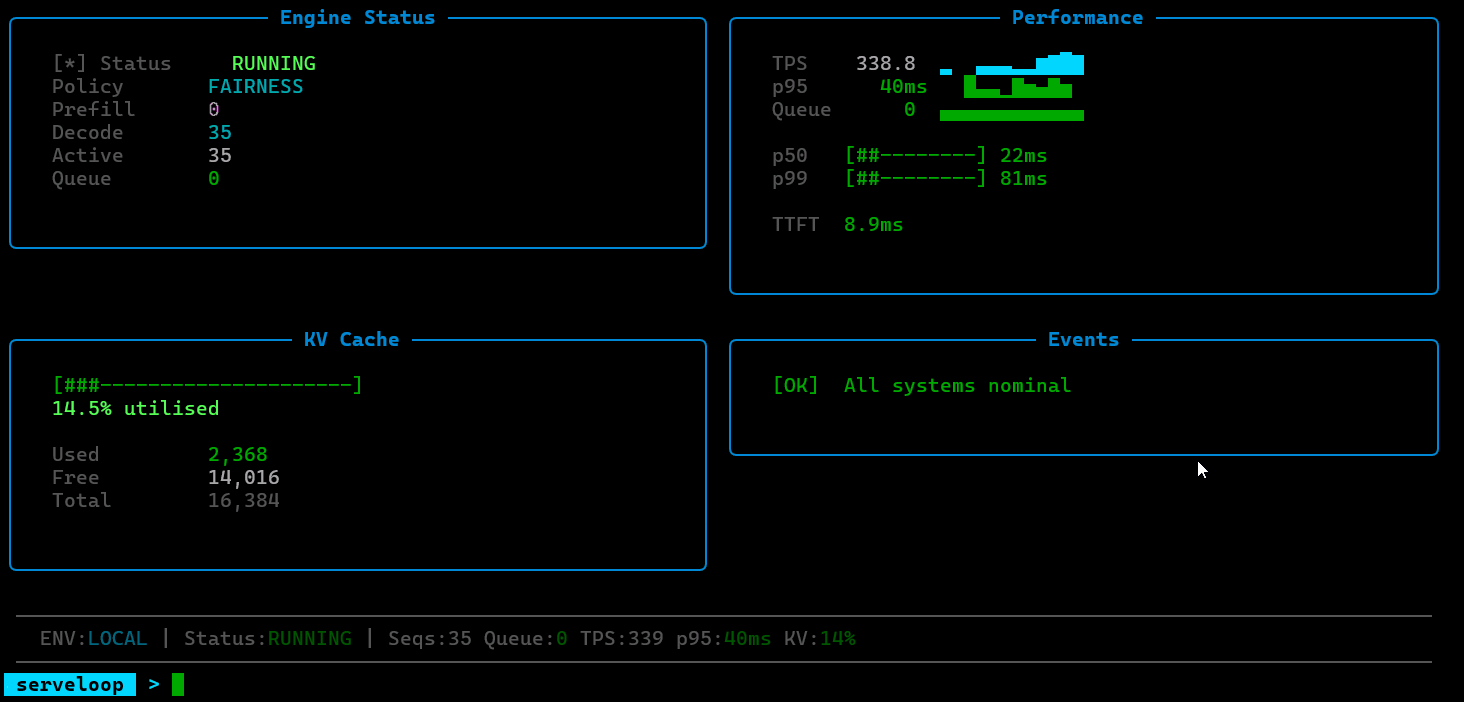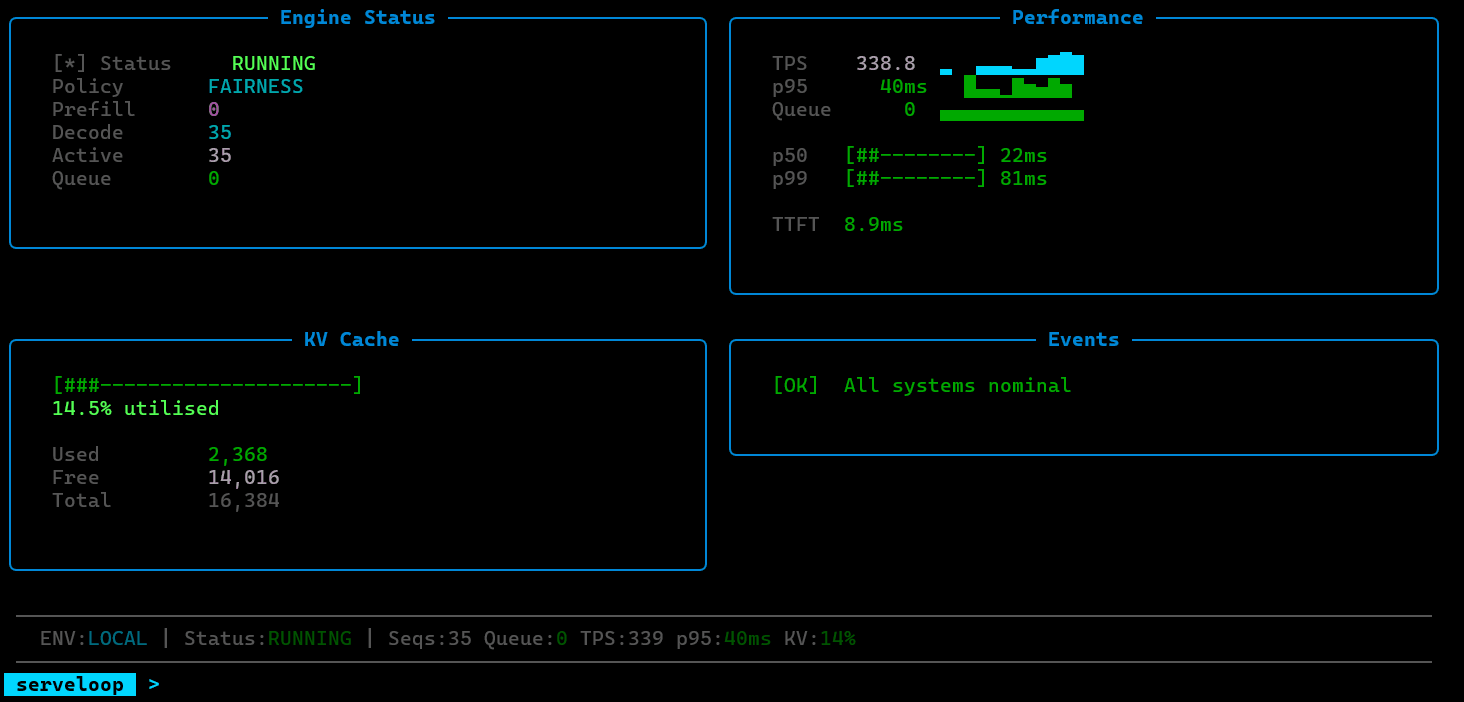
Request Manager: Handles intake, sequence tracking, and priority assignment for incoming inference requests. Manages the full lifecycle from arrival through completion, including preemption and cancellation.
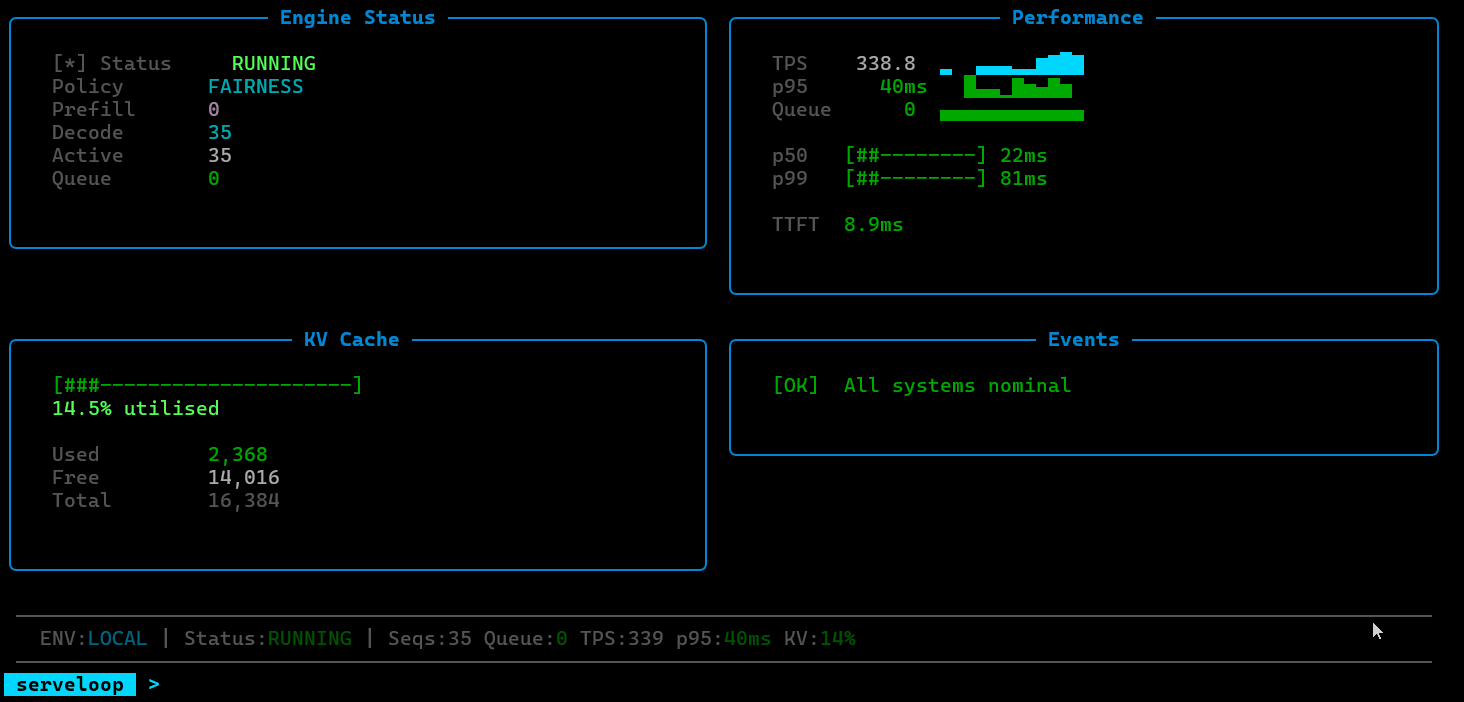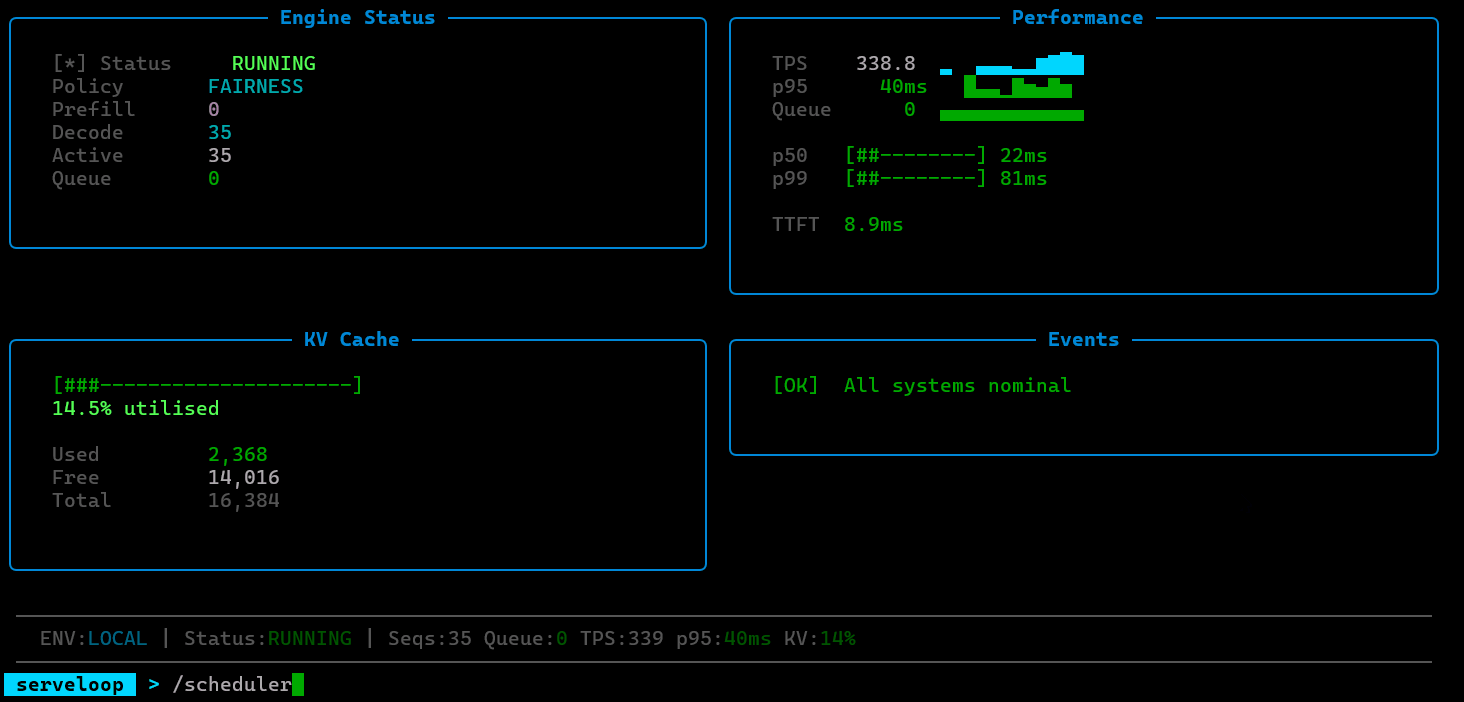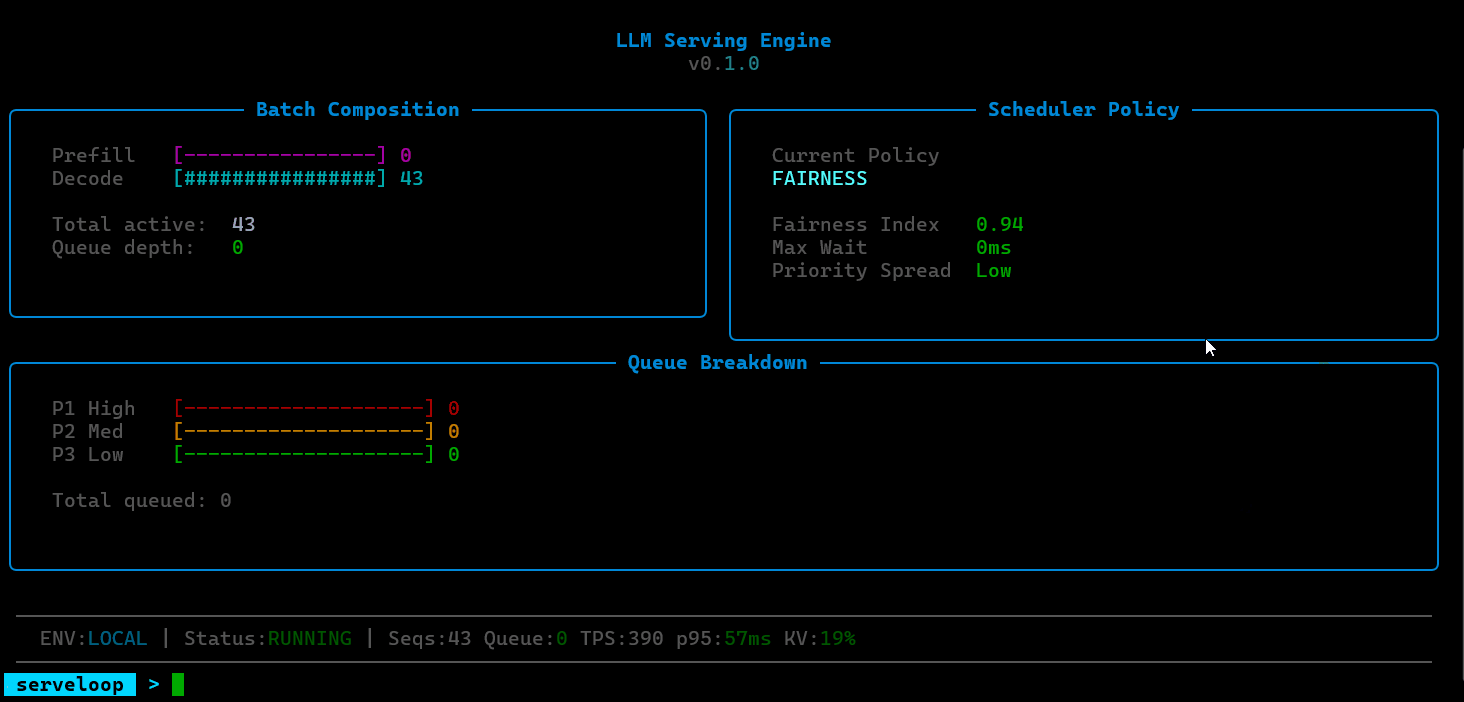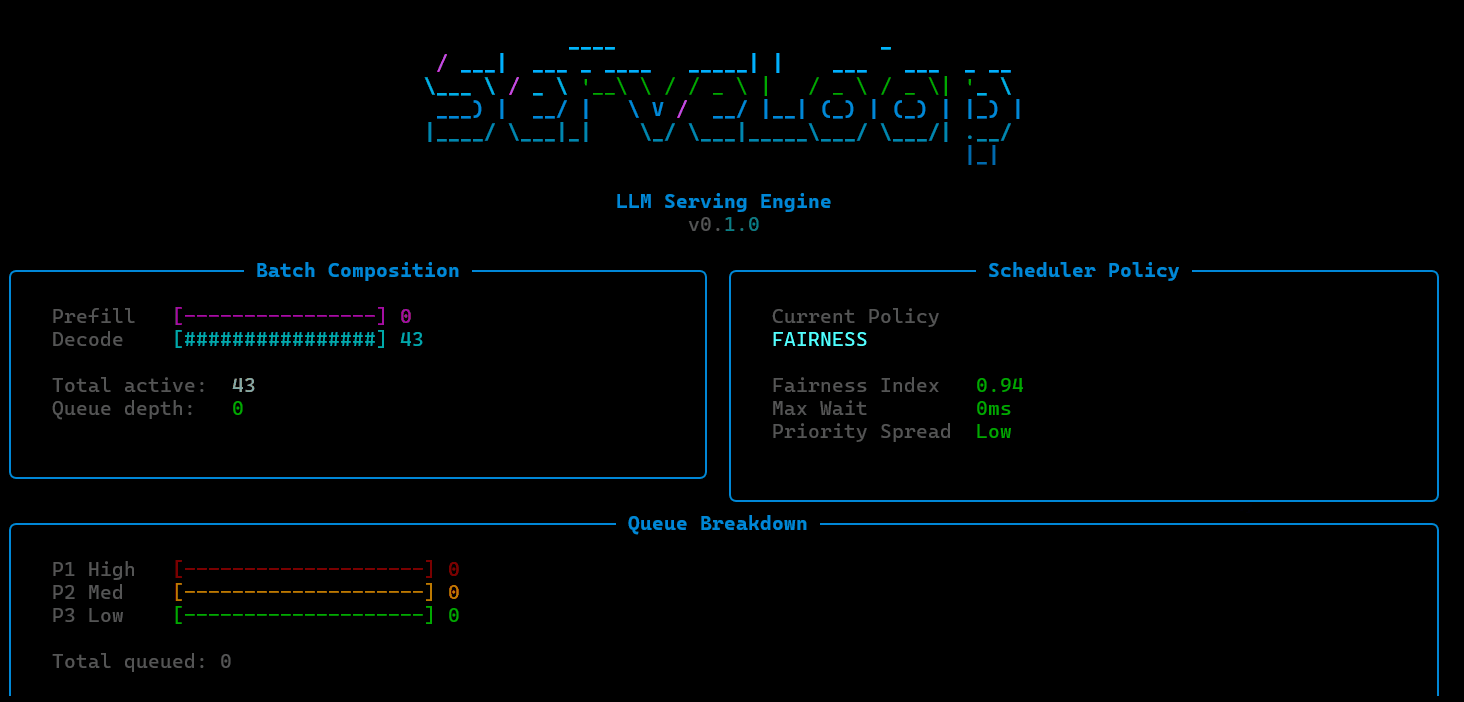
Continuous Batching Scheduler: Forms micro-batches across active requests at each decode step rather than waiting for a full batch to complete. This allows new requests to enter and completed requests to exit mid-batch, improving GPU utilization and reducing time-to-first-token.
Paged KV-Cache Manager: Allocates and frees cache blocks using a block table approach inspired by virtual memory systems. Avoids the fragmentation and over-allocation problems of contiguous KV-cache layouts, enabling higher concurrency per GPU.
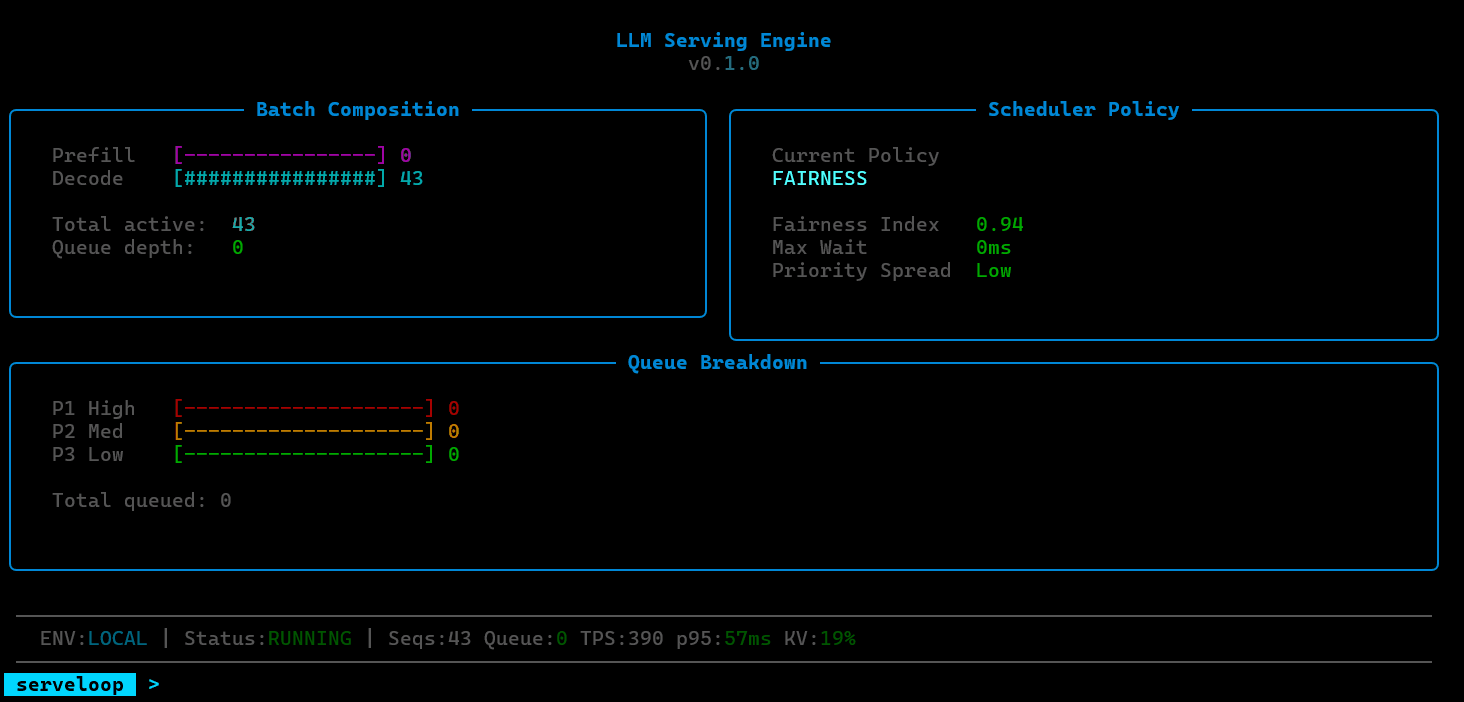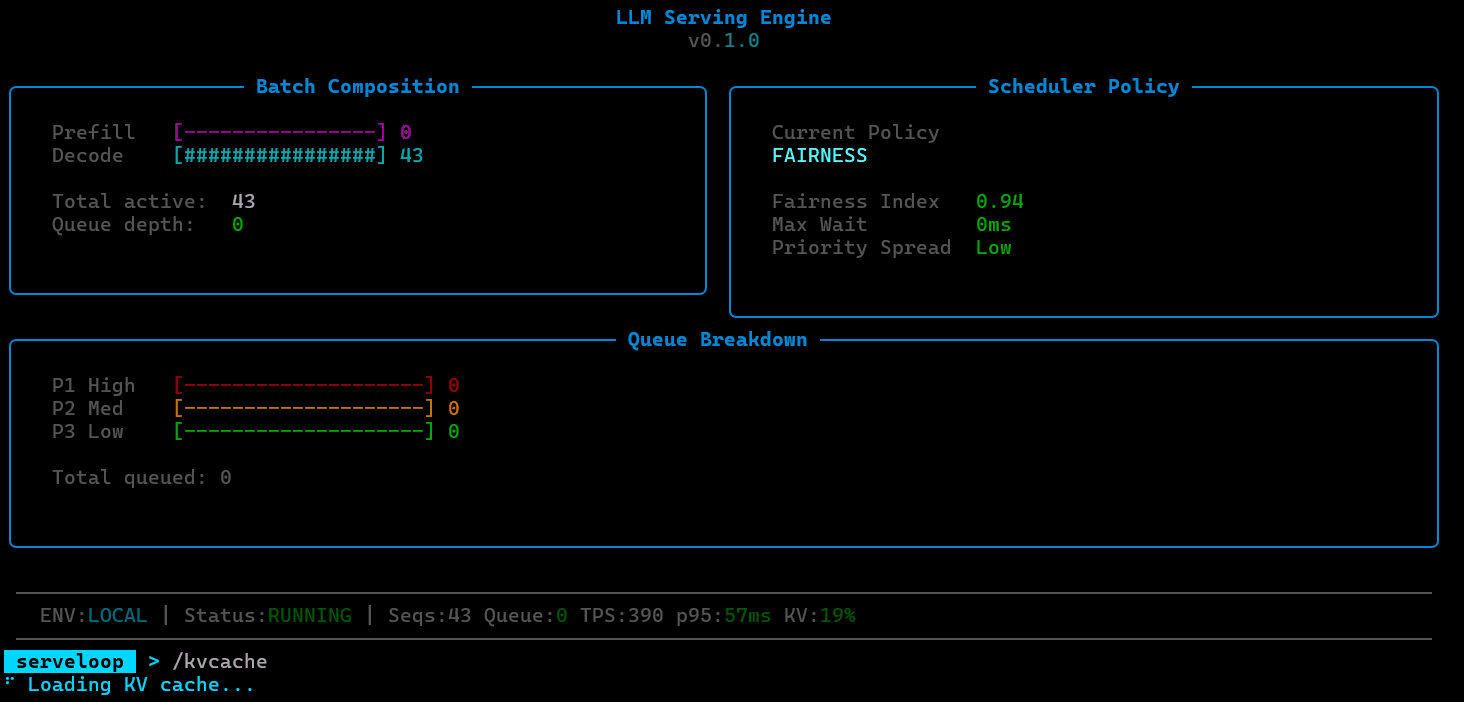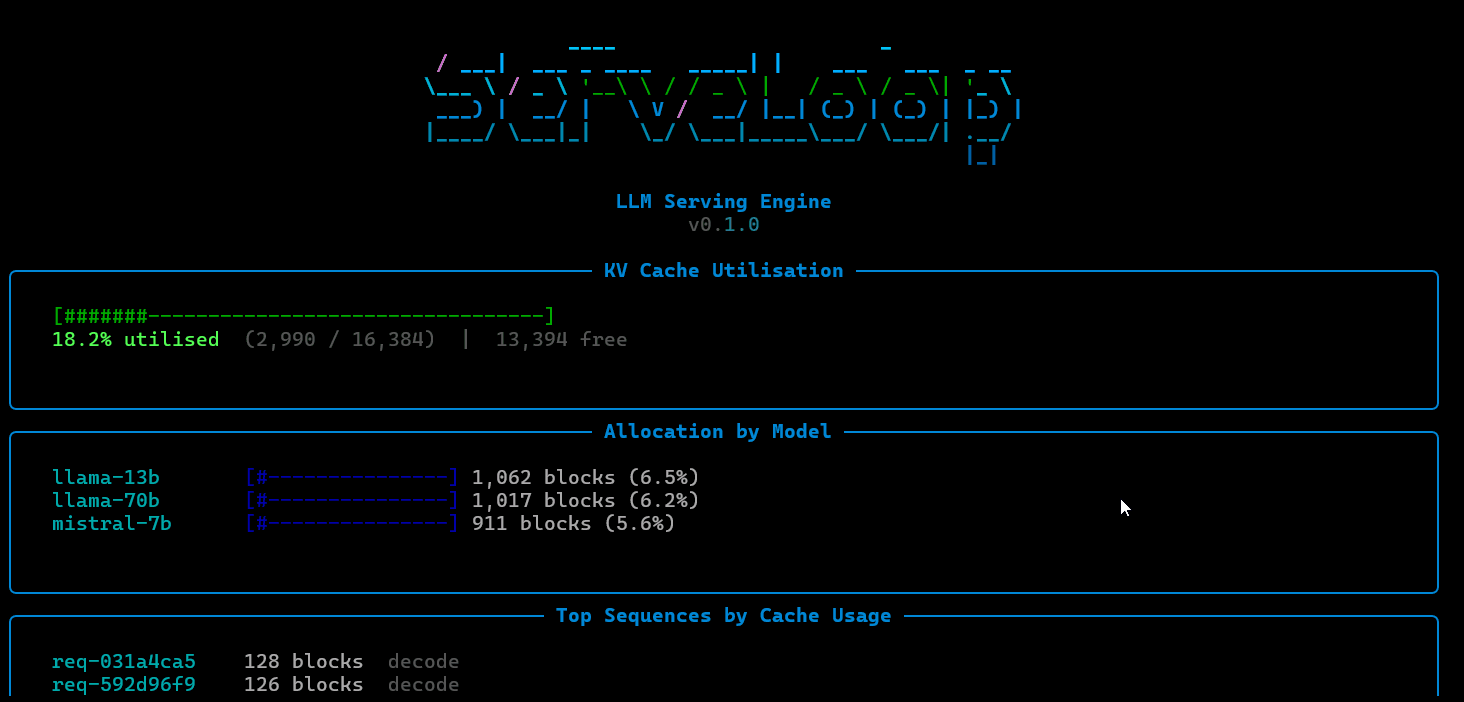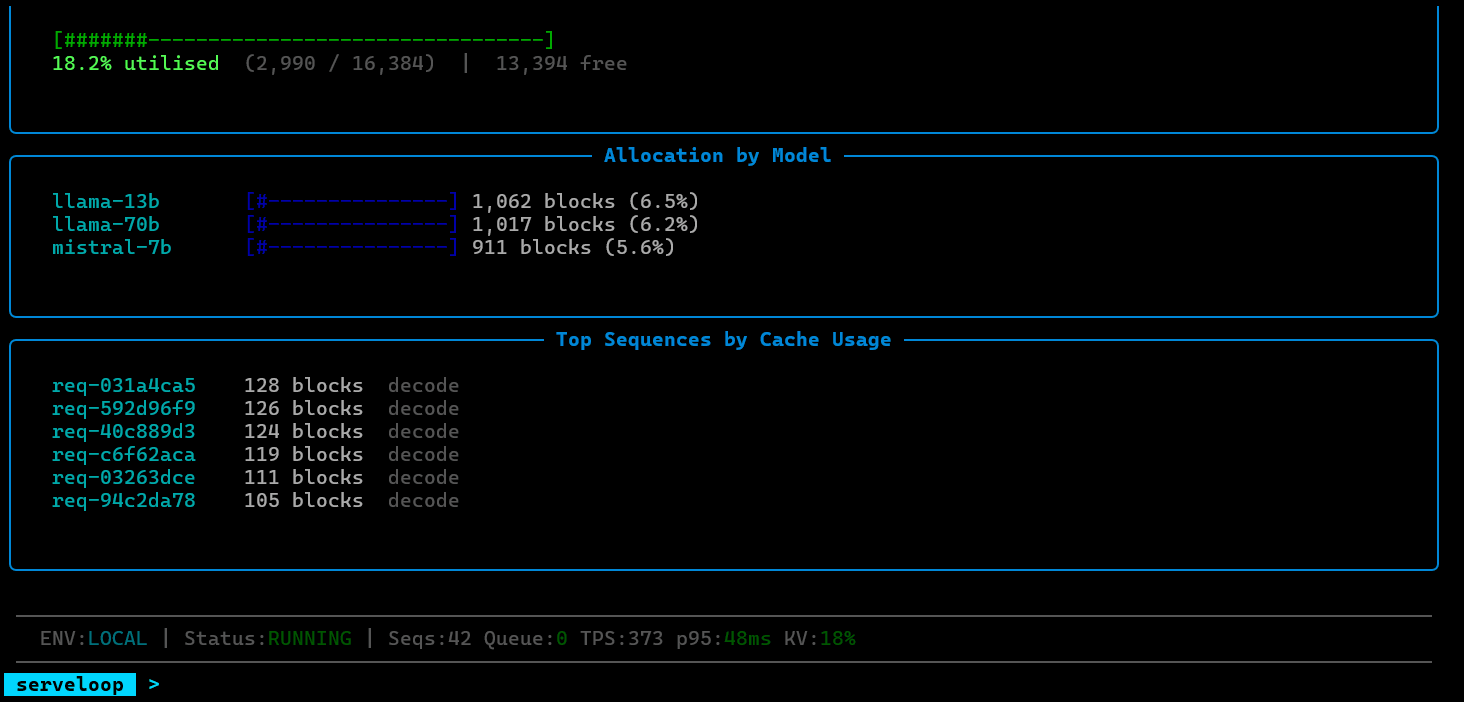
Model Execution Loop: Orchestrates prefill and decode steps, coordinating between the scheduler and cache manager to execute forward passes efficiently.
GPU Scheduling Optimization
ServeLoop includes a dedicated GPU scheduling layer designed to study the decisions that sit beneath production inference systems. This covers batch formation strategies (how requests are grouped for execution), memory-aware scheduling (ensuring KV-cache pressure doesn't force unnecessary evictions), and priority-based preemption (allowing latency-sensitive requests to jump the queue when GPU resources are constrained).
Mixed Precision Support
The engine implements BF16 and FP8 precision modes to study throughput-vs-accuracy trade-offs in serving workloads. BF16 provides a practical balance for most inference tasks, while FP8 support enables experimentation with aggressive quantization for throughput-critical scenarios — useful for understanding where precision loss becomes unacceptable and how it interacts with different model architectures.
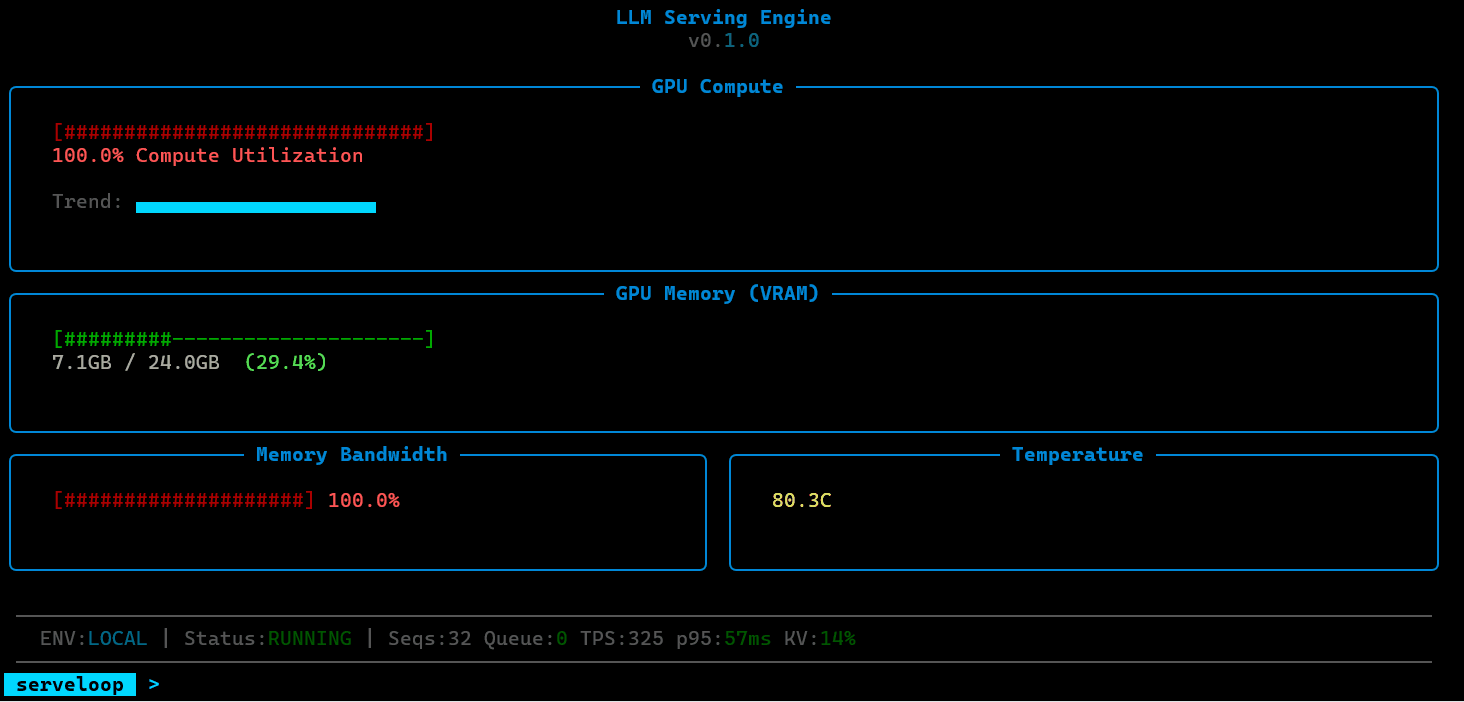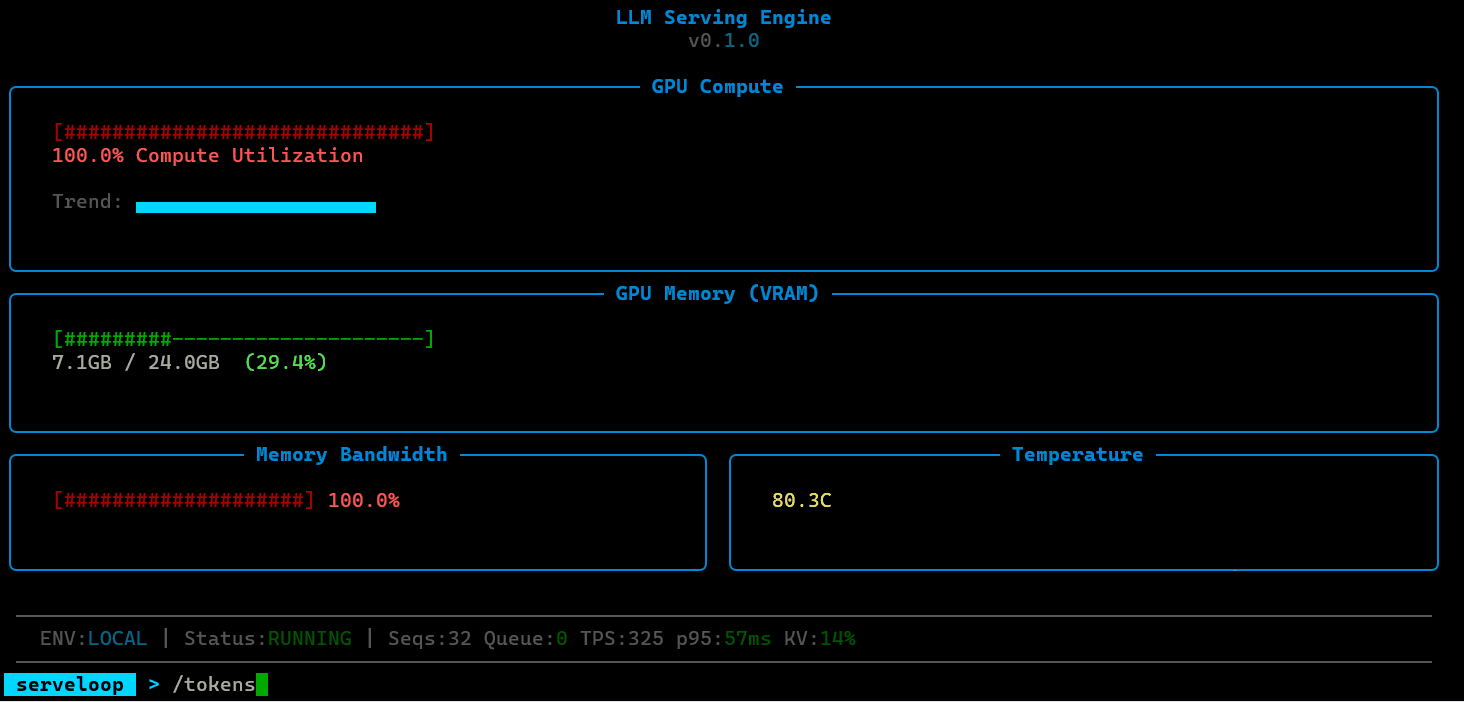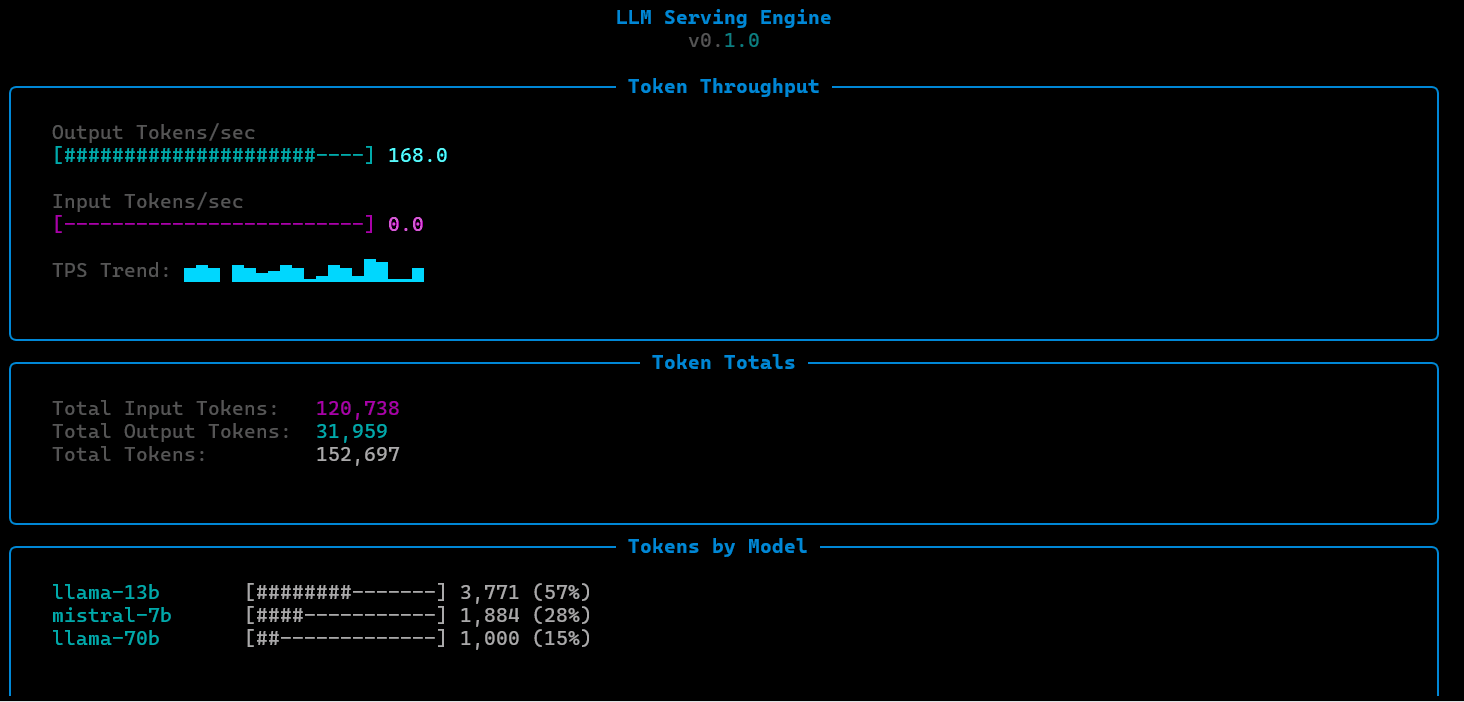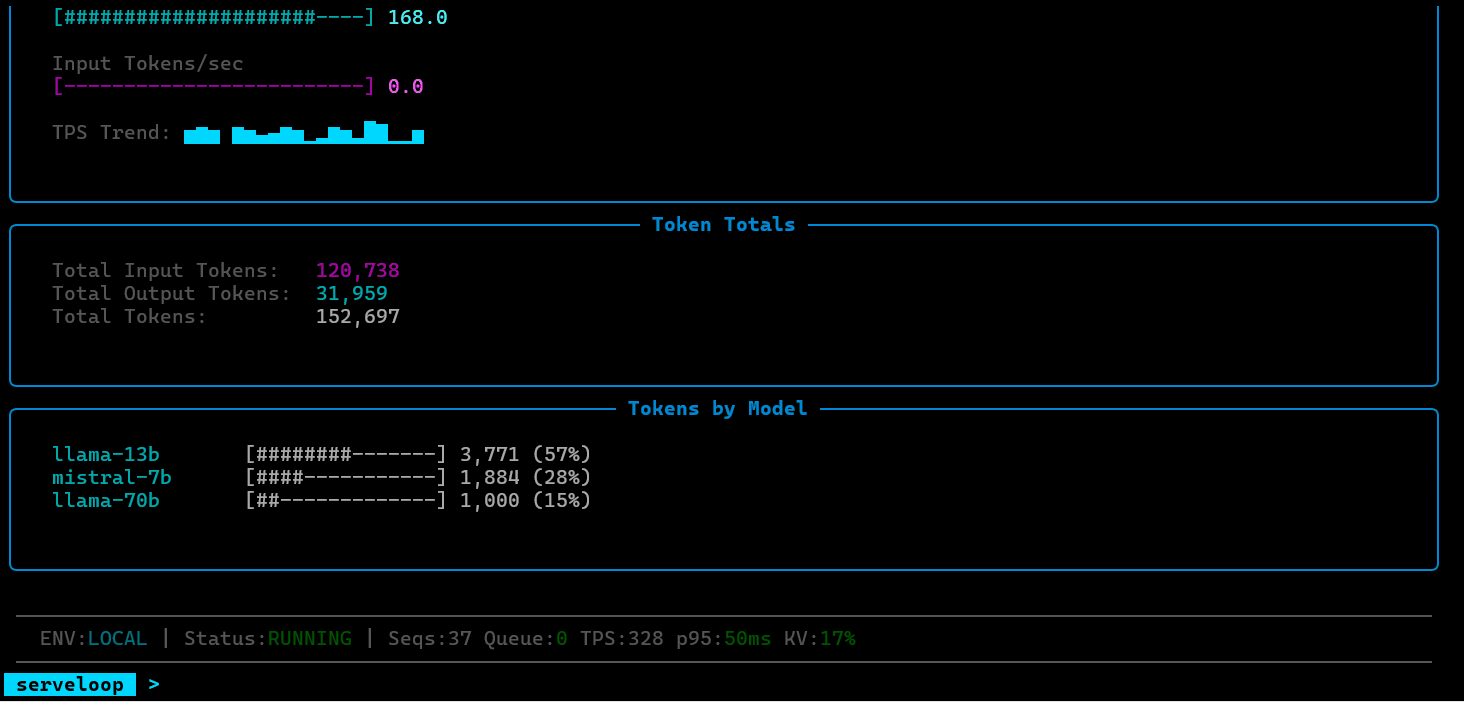
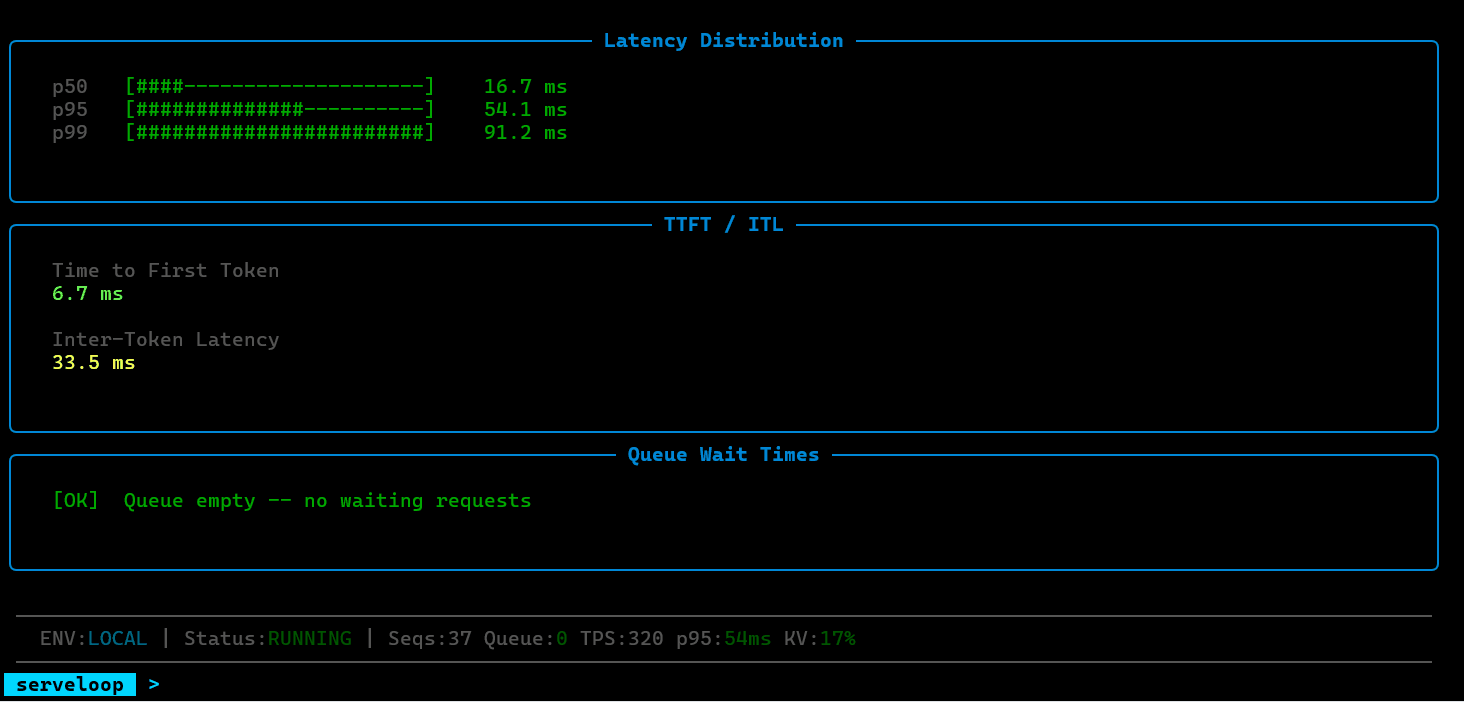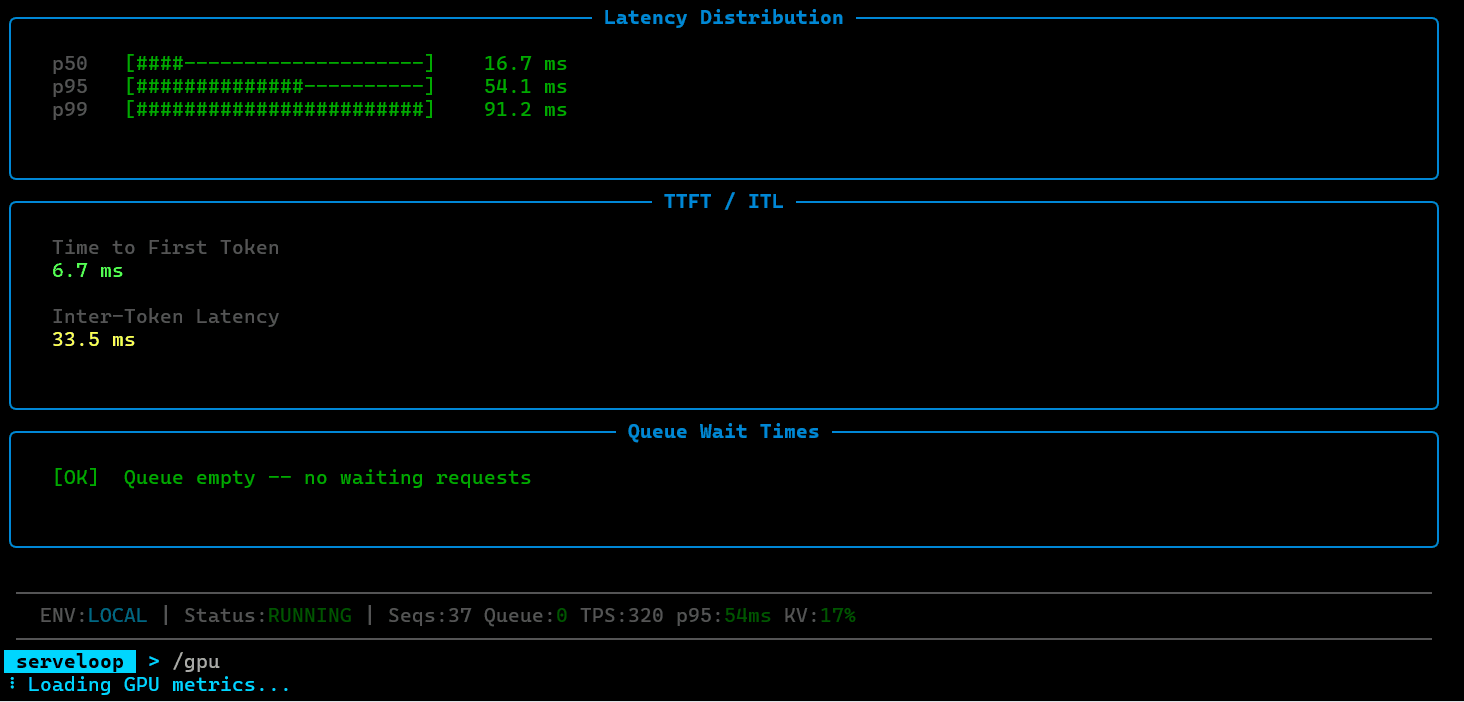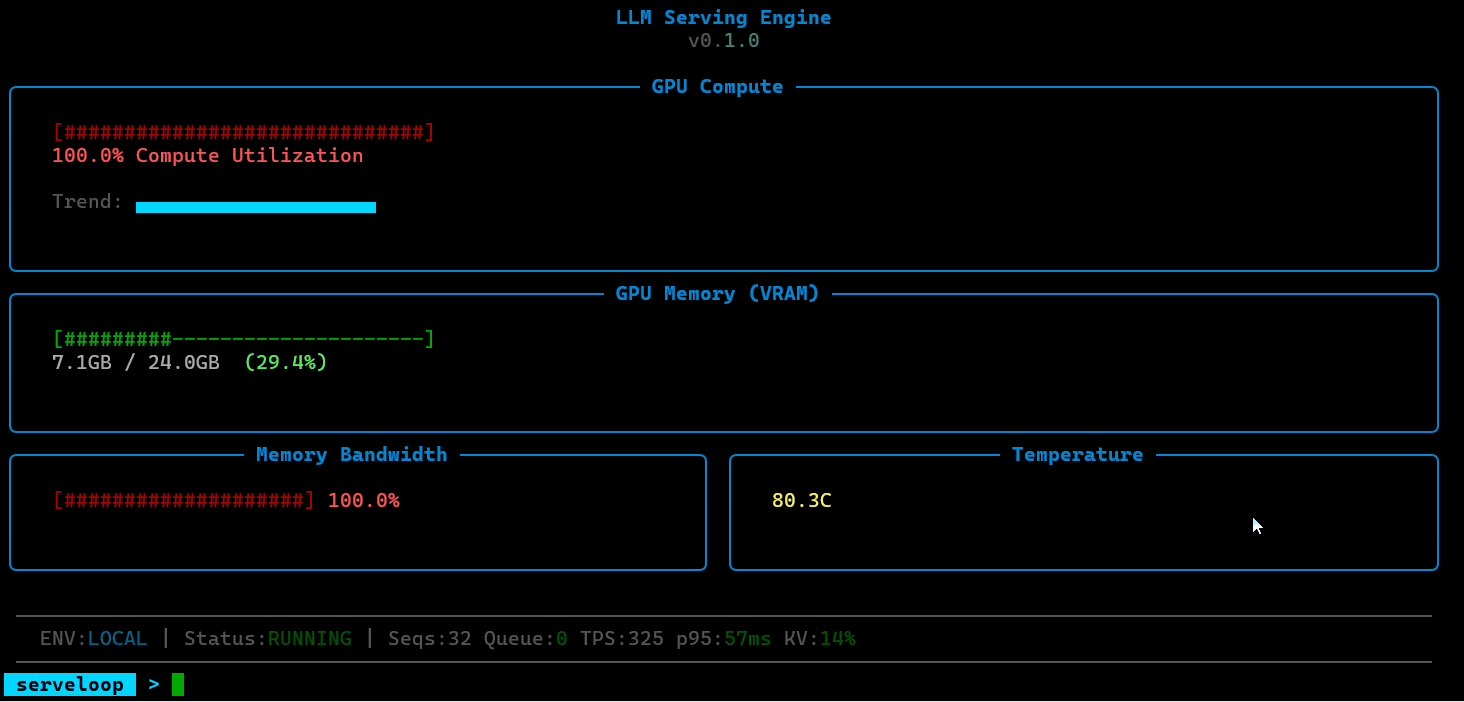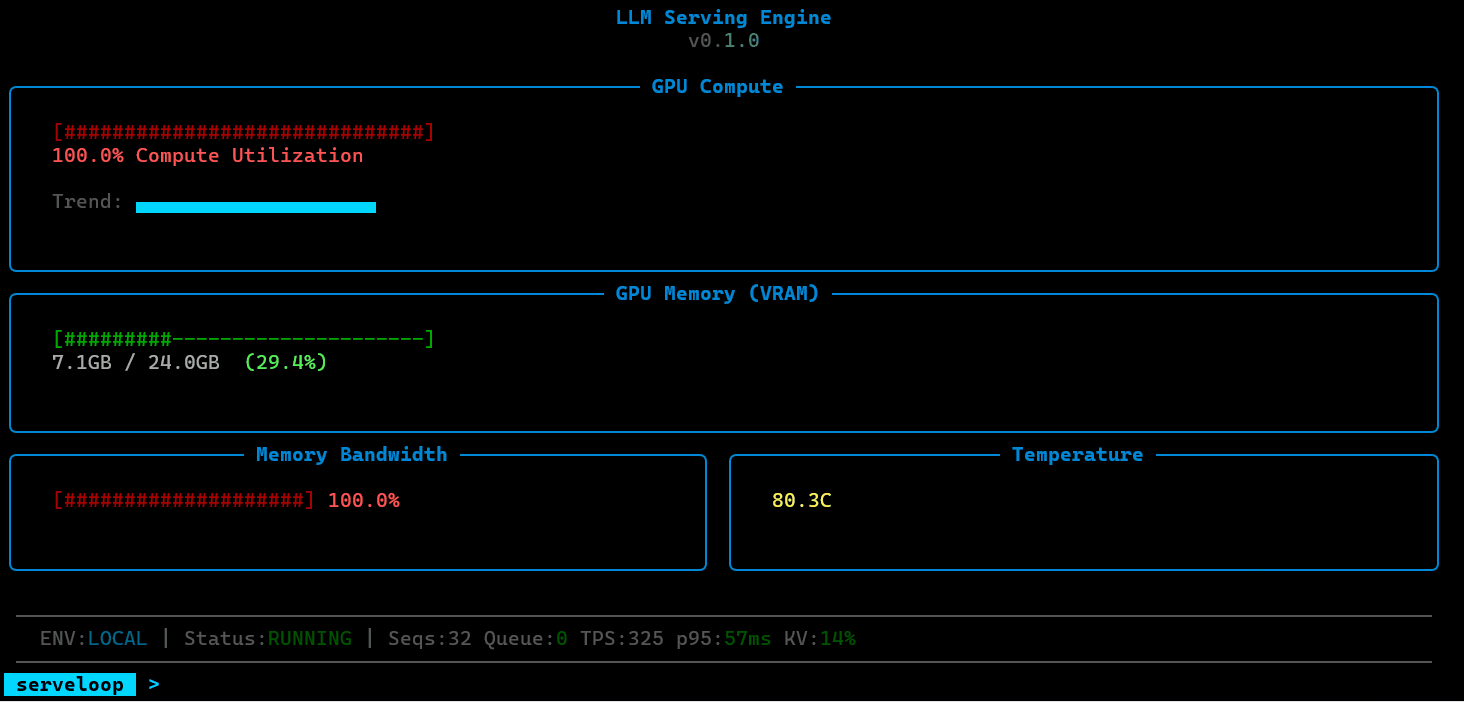
Observability
ServeLoop exposes internal metrics at each stage: queue depth, batch sizes, cache utilization, scheduling decisions, and per-request latency breakdowns (queue wait, prefill, decode). This makes it possible to trace exactly why a request was slow, where memory pressure built up, or how a scheduling change affected tail latency.
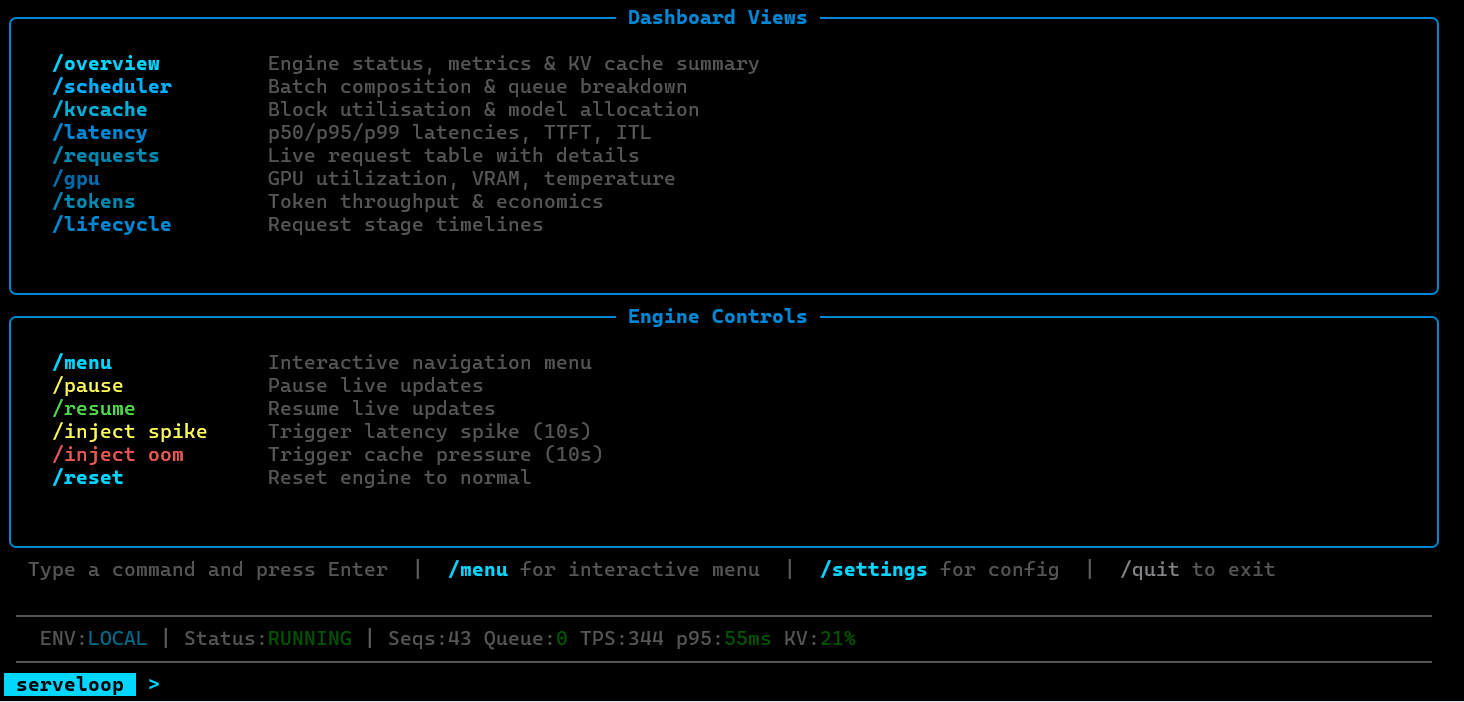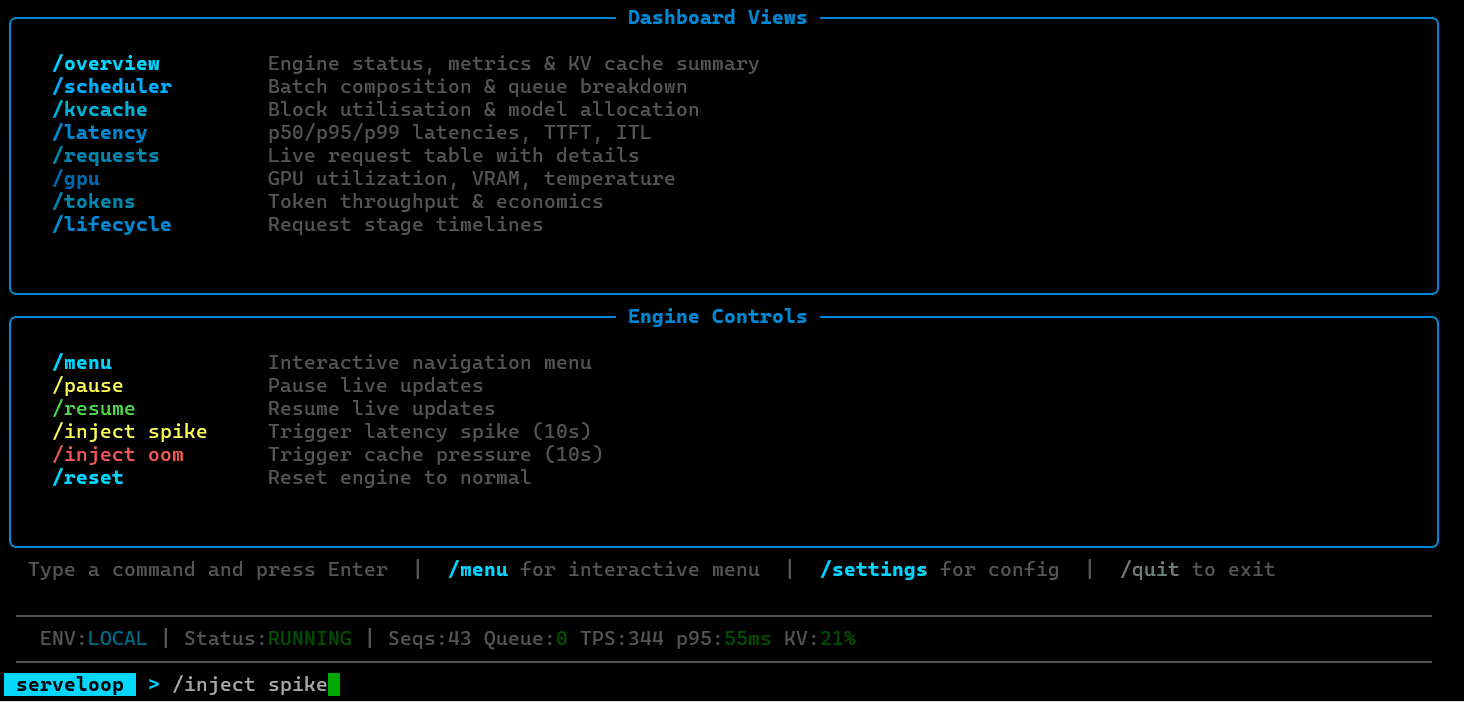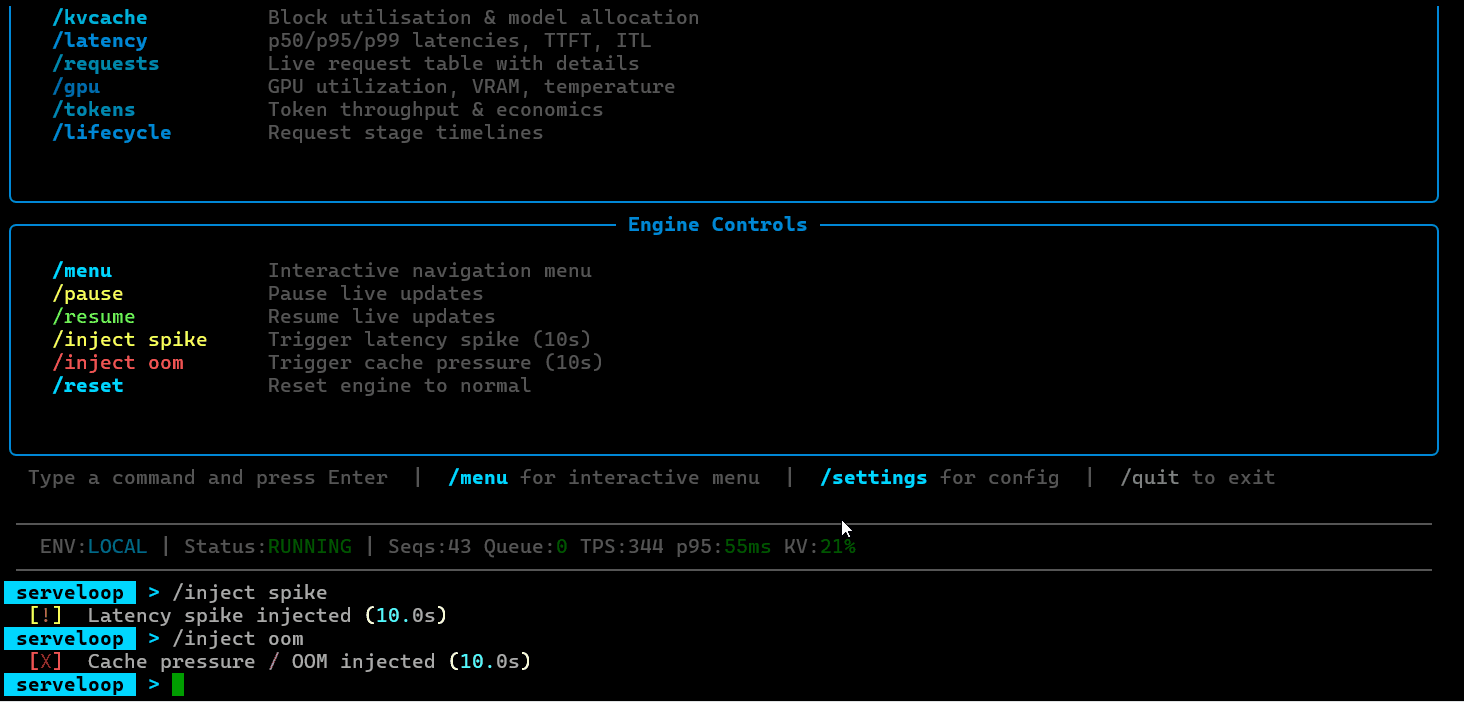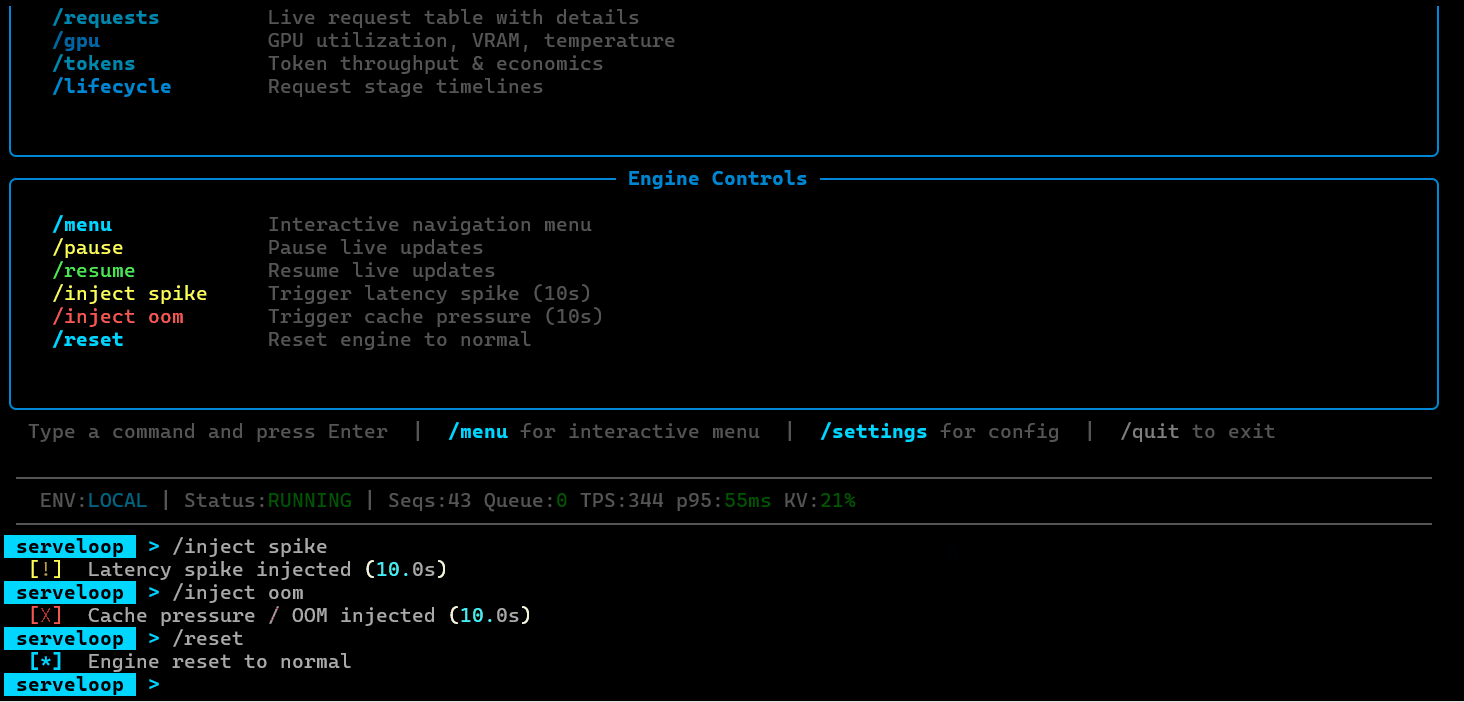
ServeLoop is being developed as a standalone OSS project. The GitHub repository will be published soon.